The software funnel problem
As I discussed in my previous entry machine learning is bringing a whole new approach to process automation and software creation.
Software has always had a major funnel problem — too many ideas & problems for the team & budget capacity.
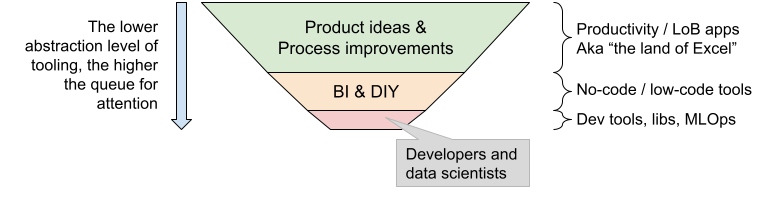
While line of business apps present streamlined and vertically specialised software, the rigidity of this and lack of extension points has meant the no-code/low-code space has generated an army of can-do power-users.
Both spreadsheet proliferation and low-code solutions have major problems going forward (mostly around visibility and change control - another post to come on that..) but it’s undeniable that productivity suites provide the life-blood of vast swathes of operations in most companies.
While low-code platforms have sought to empower processes beyond office software, data has been behind. Charts got a boost with BI suites (though often back in a pipeline problem with accessing clean/historic data) and pivot tables tried to bring the organisation of analysis cubes.
However, much of process data lives primarily in spreadsheets, or extracted from databases and LoB systems and then poured over manually. It is here that I think there is a significant gap in the supply of ML benefits.
Most tools trying to bring order to ML model delivery (and hence escape the versioning and control issues of spreadsheets) throw the baby out with the bathwater — in providing a high end delivery platform, the seat costs go up by 100x and the access by users goes down similarly.
Certainly, most ops users would get lost in an MLOps tool (they are oriented towards data scientists not casual users), but I would content that many would see benefit. Not least, finding a few nuggets of insight in data you understand (and hence can clean/judge results of) would lower the fear and resistance to wider ML usage in firms.
If every user has Excel provided, why wouldn’t they also benefit from some ML insight too? Rather than pre-filter 1000 problems down to the 3 that the DS team have capacity for, why not let 1000 users try the auto-ml button and see if it can short circuit day-to-day manual effort?